Eric
Falkenstein
Andrew
Boral
12/18/00
Moody's Risk Management Services
Published
in April 2001 Risk Professional
For quantitative risk professionals, the Merton model of default provides
a great segue into a previously qualitative and subjective area.
Using the Merton framework one can simultaneous address both individual
default risk, and then, using the same model, work this information into a
portfolio algorithm. Elegant and
efficient! To put this into
perspective, remember that loan underwriting and junk bond analysis is still a
highly narrative field, where 'the story' is often more important than any raw
numbers.
This article examines the Merton model, commenting on
its power for predicting default, and its sensitivity to refinements. Moody's
uniquely large dataset of defaulting companies gives us a glimpse of
relationships that can only be conjectured. Unlike other empirical reports which
document anecdotal, qualitative, or pricing results, this is a test of the
Merton model at distinguishing between future defaulters vs. nondefaulters.
Our findings are as follows: the model is a powerful measure of default
risk, refinements add only marginally to its power, and outside-the-box
augmentations make it significantly better.
What
is the Merton Model?
What makes the Merton model so attractive to quants is that it is so
totally familiar to them in another context.
The 'Merton Model' in credit circles refers to a model that treats equity
as an option on the firm's assets. Simply
consider equity a call option, the total
liabilities the strike price, and the
value of the firm's assets the value of the underlying asset.
This makes sense theoretically because equity is a residual: equity
holders get the upside if things go well (e.g. Microsoft), but nothing if things
go poorly (Pets.com).
Given the option framework, one can work backwards from observable
information and calculate a default metric.
Specifically, take the market value of equity (E), the volatility of
assets (sA),
the face value of liabilities (L), and the interest rate (r), and the market
value of assets (MVA). Using an options approach, the market value of equity is
the result of the Black-Scholes formula:
![]()
where
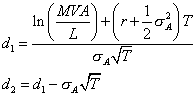
The
problem is that we have two unknowns: MVA and sA,
so we need another equation. Luckily
we have one, in that the relation between the volatility of equity and the
volatility of assets is proportional to the value of assets over equity. Specifically, the volatility of equity can be found using the
function
![]()
Given equations (1.1) and (1.2) we can solve for MVA
and sA
using standard iterative techniques that come embedded within most software
packages. The final step is to then
calculate a default metric from this information.
Given the market value of assets and a the value of liabilities, and
assuming that a default occurs if MVA<L, then the number of standard
deviations to default is expressed as:
![]()
This
final formula is a practitioner refinement to the original Merton model,
replacing the lognormal assumption with a normal approximation.
There are other refinements made to interest rate, the time horizon, the
point at which default really occurs, that are not within the Merton model
explicitly, but well within the spirit. Space
constrains our ability to explain these here, but they are relatively
straightforward adjustments that most on-the-ground practitioners are well aware
of.
Testing
Preliminaries
Before jumping in to testing results, we need to define our testing
metric. Given that most people do
not have a sufficient number of defaults to ever do these types of tests, it is
understandable that this is not an entirely familiar performance metric.
The tests below use Moody's proprietary U.S. dataset of 14,500
nonfinancial firms from 1980-2000, and 1,450 defaulting companies.
Figure 1
Power and
Accuracy Ratios
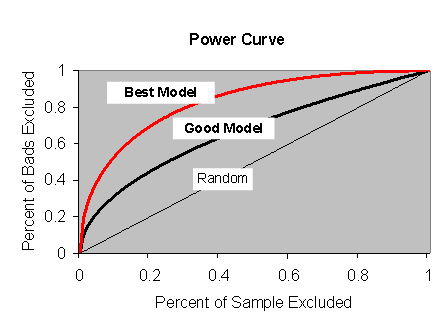
The power curve itself can be defined as follows. It maps the fraction of all companies with the worst score (horizontal axis) onto the fraction of defaulting companies within that group (vertical axis). Ideally, if the sample contained 10% defaulters, then a perfect model would exclude all those defaulters at 10% of the sample excluded: the lowest ranked companies would include all the defaulting companies. Purely uninformative and highly informative models are illustrated above.
In reality defaulters will not be perfectly discriminated, creating a curvilinear function: at 10% of the sample excluded 30% of the defaulters would be excluded, at 20% of the sample 40% of the defaulters would be excluded, etc. This creates a line that is bowed out towards the upper left (Northwest) of the chart: the greater the bow, the greater the area underneath, the better the model.
By taking the ratio of the area under the curve but above the
45 degree line, and comparing to the area under the curve of a 'perfect' model,
we can turn the power curve into a number, something we at Moody's call Accuracy
Ratios. They are somewhat like R2's of regressions, and can only be
used to compare models on identical datasets, but they provide a clear metric of
power, with 0 being totally uninformative, and 1 perfectly informative. The
higher the Accuracy Ratio, the better. In
our tests we use a 2 year horizon, because the Merton model does relatively
better at this horizon and we wish to give it every benefit.
Testing
Results
First we compare the Merton model against another well-worn measure of
corporate health. Specifically we
will use what we have found to be the best single metric of profitability, the
ratio of Net Income/Assets. At the
1 year horizon, we see that Merton model does dominate NI/A as a measure of
risk. As the standard errors on
these measures are less than 0.01, the difference reported is statistically
significant. However, it is not as if the Merton framework, by itself,
takes us into a new dimension of model accuracy.
Accuracy Ratios
US companies
1980-99, 1450 defaulting companies
|
Merton |
0.748 |
|
Net Income / Assets |
0.732 |
Can we make it better? Actually,
we already have, as we noted we used a functional form that uses the difference
between the value of assets and the value of liabilities in the strike price.
These and other adjustments are outlined in popular books on the
implementation of the Merton model (see Caoutette, Altman, and Narayanan (1998),
or Crouhy, Galai, and Mark (2001)). Thus
when we talk about the Merton model, most people refer to version 2.0, not the
1974 version.
The first check to see how sensitive the model is to refinements is to
see how much lift is generated by refinements.
Consider the following 'sophisticated alternative'.
Instead of the assumption that default can only occur at maturity, we
will instead use a barrier option approach, so that a default occurs if the
value of the firm falls below the distress point
at any time prior to maturity. The
results, in Table 2 below, suggest
that the Merton model does make a rather strong improvement over the naive
method for integrating market information.
Yet while the barrier option refinement is in the right direction, it is
sufficiently modest to be considered not worth the trouble.
Accuracy Ratios
US companies
1980-99, 1450 defaulting companies
|
Merton |
0.746 |
|
Barrier |
0.748 |
Thus the Merton model is better than other simple metrics of firm health,
such as NI/A, not materially affected by refinements of barriers.
But what about an outside-the-box refinement?
Some would say this is like painting a mustache on the Mona Lisa, but
this isn't art, its engineering. Outside-the-box
refinements have been going on since Ptolemy's mapped the heavens.
A
Hybrid Approach
A specific alternative we want to test is our best version of the Merton
model, versus a hybrid approach that uses the Merton and NI/A.
Theoretically, all the needed information needed for default prediction
is in the equity price and the liability structure. A compelling argument for this view is that if equity
information and the capital structure is insufficient, that would imply you
could outperform an equity benchmark like the S&P500. Many studies have demonstrated that professionals rarely
outperform such benchmarks over long periods.
The rebuke 'if you're so smart why aren't you rich' really rings true for
people who say equity markets are clearly and often irrational.
Yet this analogy is not so tight. If
the model is perfectly specified, there is a one-to-one mapping between market
information and default probabilities (or at least, a rank-ordering of default
propensities). If the model is
imperfectly specified, however, other information may help predict default rates
even though it can not help predict future equity prices.
To add the information together, Merton and NI/A, we need to normalize
these inputs so that their their impacts are equally weighted.
To do this, we converted both variables to percentiles and added them
together. A high Merton percentile
means a company is many standard deviations from its default point; similarly, a
high NI/A ratio is a high percentile, and also implies good credit. Thus we simply added the two percentiles together for this
simple hybrid model.
The result is in Table3. Our best Merton model, adjusting for barriers, a perpetual
options, interest rates, and several other items unmentioned, scored a 0.75.
Adding NI/A upped the score to 0.799.
Quite an improvement, much more than any refinements to the Merton model
2.0.
Table
3. Adding Excluded Variables
Accuracy Ratios
US companies
1980-99,
1450 defaulting companies
|
'Best' Merton Model |
0.748 |
|
Simple Merton and Net Income/Assets |
0.799 |
Conclusion
Criticizing a model as being 'insufficient' is
usually a straw man argument, yet there does exist an energetic group who
actually hold this extreme view for the Merton model: that it's not only timely
and powerful, but sufficient. While
the information above is not a complete analysis, it hits on our strongest
argument. It is purely an empirical
issue as to whether the Merton model, with all the refinements to interest
rates, liability structure, default points, and other inside-the-box
adjustments, says everything there is to say about default probabilities.
Our data suggest it doesn't.
While insufficient, the Merton model is a valuable
part of any credit analysts toolkit. At Moody's we find it useful information
for our traditional analysts, and also for our own hybrid quantitative default
model that uses equity information and financial ratios.
References
Crouhy, Michel, Dan Galai, and Robert Mark.
Risk Management. McGraw-Hill, 2001.
Caoutette, John, Edward Altman, and Paul Narayanan.
Managing Credit Risk. John
Wiley & Sons, 1998.
Merton Model Merton Model Merton Model Merton Model Merton Model
Credit Risk Default Risk Credit Risk Default Risk Credit Risk Default Risk