


Relative Utility
Relative Utility Functions Imply a Zero Risk Premium
Economists generally think of self interest as maximizing the present value of one’s consumption, or wealth, independent of others. Wealth can be generalized to include not just their financial assets, but the present value of their labor income and even public goods. Adam Smith emphasized a self-interest that also recognized social position and regard for society as a whole, but this was well before anyone thought of writing down a utility function, which is a mathematically precise formulation of how people define their self interest.
But what if self interest is primarily about status, and only incidentally correlated with wealth? A lot, it turns out.
In a book titled Human Universals, professor of anthropology Donald Brown listed hundreds of human universals in an effort to emphasize the fundamental cognitive commonality between members of the human species. Some of these human universals include incest avoidance, child care, pretend play, and many more. A concern for relative status was a human universal, and relative status is a nice way of saying people have envy and desire power [status seeking, benchmarking, all fall under this more sensational description, envy].
The idea that ‘incentives matter’, and that people generally act in their material self interest, is a powerful assumption. Alternative conceptions of human action, such as that people care mainly about their community, country, or God, are considerably more convoluted in explaining, say, why stock prices are uncorrelated from one day to the next.
The problem with the utility function is not solely related to asset pricing puzzles. It is useful to note other conspicuous areas where the utility function fails.
Mathew Rabin won a MacAurthur Foundation genius grant, and John Bates Clark Medal for showing (Rabin 2000) that one can apply the fact that concave functions to show that if one has the above utility, and one choose to turn down a 50-50 bet to lose $10 or gain $11, one would not accept a bet to lose $100 and win an infinite amount of money. This absurdity highlights a profound problem with our fundamental conception of utility. Something is clearly amis with the standard model, or perhaps, a curiosity like the breakdown of Newtonian physics near the speed of light.
Another prominent anomaly to utility functions is the Easterlin Paradox, the finding that after a minimum level of income has been achieved, measured happiness does not appear to rise much. If people's happiness is a function of wealth, we are much wealthier than our ancestors but not much happier. This has been documented in many countries, such as Japan, where income rose five-fold from 1958-1987, yet people remained about as happy. This puzzle been addressed in such books as Gregg Easterbrook's The Progress Paradox, David Myer's The American Paradox, Barry Schwart's The Paradox of Choice. The paradox is because if people are primarily self-interested wealth maximizers, they should becoming happier as wealth has increased dramatically in the twentieth century, though if people are mainly interested in their status, this makes perfect sense.
Libertarians are quick to highlight criticisms of Easterlin’s Paradox, because they can’t stand the thought that people are primarily status seeking. This is because the assumption of simple wealth maximization has the nice property that liberty maximizes people’s wealth and happiness; if people are primarily status seeking, letting people alone won’t necessarily increase aggregate welfare, because there will always be an underclass that is relatively poor and unhappy. Wealth maximization in that circumstance changes only who is happier, not total happiness.
Economists strongly prefer the idea that people are merely wealth maximizing agents because this generates tractable models, and economists are primarily modelers. Envy would invalidate many models, if not entire subdisciplines, because in that case one cannot aggregate preferences into one person, as it makes no sense to talk about the aggregate happiness of people, when their happiness depends mainly on their relative positions. Economists like to add these curiosities outside models, but clearly the value of GDP is ambiguous if envy is primary. As the old can opener joke goes, economists like the wealth only self-interest assumption because it generates unambiguous answers.
Over the years, economists have become good at defining exactly what kind of utility allows them to generate tractable models. While some assumptions, such as assuming everyone has the same beliefs and preferences, have been attacked, they generally have not made much of a difference. But these are rather small compared to the idea that the utility function people are maximizing has 'constant relative risk aversion'. The idea here is that while we think it fundament that people have utility increasing in wealth at a decreasing rate, the specific functional form is actually highly circumscribed.
The problem is, we know that the utility curve becomes come much flatter as one rises in wealth, implying rich people are almost indifferent to wealth, and almost indifferent to risk. It seems implausible that risk preferences for you average person have declined over the past millennium or century, as this would be reflected in the risk free rate, which has not changed considerably over the past 150 years. So, economists discovered we must have 'constant relative risk aversion', so that 'risk' is relatively the same regardless of how much wealth you have: a 10% gamble always feels the same. If risk preferences were not of this sort, one can be presented with a series of risks, each of which one finds acceptable, that lead one into any position; the other party—say, the casino management—can always make a profit, and essentially "pump" money out of players. The modern notion of risk aversion that does not lead to an absurdity is that we value ‘stuff’ via a function
![]()
where a is the risk aversion constant—usually between 3 and 10—because only that function would imply the consistent interest rates we have seen over the past thousand years. How plausible is it that humans have this kind of mathematically precise instinct?
An early paper by Abel (1990) showed that if people were interested in the consumption relative to prior periods (habit persistence) or prior aggregate consumption (the keeping-up-with-the-Joneses), the spread between the expected return premium for stocks, and the risk-free rate, diminished considerably, potentially explaining the seemingly ‘too high’ equity premium puzzle. His utility function was of the form
![]()
Where c is the per individual consumption, and C the aggregate consumption. Gali (1994) expands this so that aggregate (C ) and individual (c ) consumption have more independent exponents
![]()
where γ <1 and a>0. So, if γ<0, there are consumption externalities, "keeping up with the Joneses” effects that cause people to herd into aggregate risky wealth investments. In both Gali and Abel, by linking the individual consumption with aggregate consumption, one basically makes the objective criterion less volatile: in big market moves, you move with everyone else. This leads to ‘lower risk’ than a case where you compare yourself to an absolute standard.
With Gali’s function, the risk free rate is not implied to be as implausibly volatile as in the Abel model. While Gali’s approach can cause the the required risk premium to be lower than in the standard CRRA approach, if γ<0, there are public goods aspects to aggregate consumption, and this would increase the theoretical equity premium. Thus, Gali’s approach did not was not to decrease the risk premium, but rather to highlight that taking into account other considerations affects asset returns.
In DeMarzo, Kaniel, and Kremer (2004), the utility function is not assumed, but rather endogenous. They present a model where agent’s utility is a function of two types of consumption: standard goods, and positional goods. Positional goods are things like mates, beachfront properties, or table seatings at a restaurant, whose supply is unaffected by aggregate wealth. They create a ‘complete’ model by having the positional goods proxied by service consumption in period 2 provided by a fixed amount of labor, so that regardless of the total wealth in the model, people will be competing for access to services in exactly the same way. Thus, the positional nature of the service goods is endogenous to the model. Their utility function is given by
![]()
here a is the standard coefficient of risk aversion, and cg the consumption of goods, cs the consumption of services. Total output for the economy is a function of a fixed amount of services (e.g., the same number of barbers regardless of societal wealth), and a random production from the risky asset (the technology shock). As the production of services is fixed by the size of the labor pool and unaffected by the output from 'risky' investment, the relative size of the ‘positional goods market’, due to services, can lead to lower than otherwise risk premiums. In fact, under some parameterizations, the risk premium can be zero or negative.
Neither Gali or Abel explain ‘bubbles’, that is, cases where rational agents generate situations where the long-term return is negative, but agents invest nonetheless. The advantage of the Kremer and DeMarzo model is not only that the relative orientation is endogenous (because of positional goods), but also that certain equilibrium lead to negative expected returns in the risky asset. This can happen in the Kremer and DeMarzo due to decreasing returns to scale in the risky asset. If enough people invest too much the return can go negative but still elicit investment because people want to keep up with the Joneses.
Kremer and DeMarzo suggest this is relevant to bubbles, but the abstract model is ambiguous: certain parameterizations lead to a negative risk premium for the entire economy, which has only one risky asset bu most do not.
In general, adding a ‘relative wealth term’ implicitly via positional goods, or explicitly, generates a lower, perhaps negative expected return. My contribution is to say definitively that if people are status oriented, there is no risk-premium. End of story. There is no reason to subtilize this idea within a larger model so that it has only a selective implication. For example, Roussanov (2010) has a model with a utility function each period of
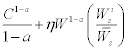
Where C is consumption, W is wealth, and the agent is comparing his wealth to others in the second term. Embedding the relative wealth/status/consumption idea within a conventional model makes it easier for the academy to digest, but the generality to accommodate the current model, and the implications of relative status, make the results ambiguous. These models are non-falsifiable (some assets may show no risk premium), and do not advance the science of finance because it allows professors to continue teaching the manifestly unhelpful idea that expected returns are increasing in risk, and only risk, properly defined.
My Contribution
The purpose here is to present a model where there is no risk premium in equilibrium. The models presented are simple, but an even simpler example is useful in seeing the driver of this the result. There are two assets, X and Y, and two states of nature, 1 and 2. An investor faced with asset X or Y can see the following returns:
Table 3.1
Payoffs to Assets X and Y in States 1 and 2
Total Return Avg. Relative Return
X Y X Y
State 1 0 –10 –5 5 –5
State 2 20 30 25 –5 5
As shown in Table 3.1, Y is conventionally considered riskier, with a 40 point range in payoffs versus a 20 point range for X. Yet on a relative basis, each asset generates identical risk. In State 1, X is a +5 out performer; in State 2, X is a -5 underperformer, and vice versa for asset Y. In relative return space, the higher absolute volatility asset is not riskier; the reader can check this for any example in which the two assets have the same mean absolute payout over the states (i.e., the average for asset X and asset Y is the same) The risk in low volatility assets is its losing ground during good times. If X and Y are the only two assets in the economy, equivalent relative risk can be achieved by taking on an undiversified bet on X or Y, which is identical to taking a position on not-Y and not-X. The positions, from a relative standpoint, are mirror images. Buying the market, in this case allocating half of each, meanwhile, generates zero risk.
Everything really flows from this simple insight. Implicitly the equilibrium and arbitrage derives from the fact that when relative portfolio wealth is the argument in the utility function, systematic volatility is symmetric, as the complement to any portfolio subset will necessarily have identical — though opposite signed — relative return. Thus gains from trade can always be made if there is a risk premium. The following highlight how this plays out in models that traditionally generated risk premiums.
A. The Arbitrage Model
Assume an economy with risky assets that are a
function of a market factor ![]() . For any investor i
who chooses an asset with a specific beta
. For any investor i
who chooses an asset with a specific beta ![]() ,
returns are generated via the factor model
,
returns are generated via the factor model
![]()
Where ![]() is a constant for an
asset with the specific beta
is a constant for an
asset with the specific beta ![]() , and
, and ![]() . We will assume no idiosyncratic risk from
assets, because the gist of this approach is without loss of generality.
. We will assume no idiosyncratic risk from
assets, because the gist of this approach is without loss of generality.
The return on the risk-free asset is the constant![]() . The market price of all assets, risky
or risk-free, are assumed equal to 1, so we are solving for a
. The market price of all assets, risky
or risk-free, are assumed equal to 1, so we are solving for a ![]() and
and ![]() such
that this is an equilibrium. That is, the prices are set to one, but the
returns are free parameters.
such
that this is an equilibrium. That is, the prices are set to one, but the
returns are free parameters.
The market return in this model is the benchmark to
which investors compare themselves, just as mutual fund managers typically try
to outperform their benchmark. Their objective is to maximize their out
performance, subject to minimizing its variance. Define ![]() , which is the relative performance of
investor i to the market return
, which is the relative performance of
investor i to the market return
![]()
Here ![]() is the return on the
investor’s portfolio with its particular factor loading
is the return on the
investor’s portfolio with its particular factor loading ![]() ,
and
,
and ![]() is the return on the market. Investors
all have the simple objective of maximizing
is the return on the market. Investors
all have the simple objective of maximizing ![]() while
minimizing a proportion of its variance, as in
while
minimizing a proportion of its variance, as in
![]()
![]() . Substituting
equation (3.6) into (3.7) generates
. Substituting
equation (3.6) into (3.7) generates
![]()
Since ![]() is the only random
variable, the variance of outperformance is just
is the only random
variable, the variance of outperformance is just
![]()
Equation (3.10) implies that the beta bet is basically
risky to the extent it deviates from the average, in either direction. We can
replicate the relevant risk of a stock with a beta of ![]() ,
,
![]() , via a portfolio consisting of
, via a portfolio consisting of ![]() units of the market portfolio, and
borrowing
units of the market portfolio, and
borrowing ![]() units of the risk-free asset (cost is
units of the risk-free asset (cost is ![]() , same as for the stock, as all assets
have a price of 1 by assumption). Arbitrage then implies that these have the
same expected returns, so
, same as for the stock, as all assets
have a price of 1 by assumption). Arbitrage then implies that these have the
same expected returns, so
![]()
The LHS of equation (3.11) is the market portfolio
levered ![]() times by borrowing (1-
times by borrowing (1-![]() ) in the risk-free asset in financing,
while the RHS is the unlevered
) in the risk-free asset in financing,
while the RHS is the unlevered ![]() asset portfolio via
equation (1). They have the same factor exposure, and cost the same, so they
should have the same return in equilibrium. Thus equation (3.11) implies
asset portfolio via
equation (1). They have the same factor exposure, and cost the same, so they
should have the same return in equilibrium. Thus equation (3.11) implies
![]()
This allows us to replace the ![]() with
with
![]() in equation (3.12) and leads to the
factor model
in equation (3.12) and leads to the
factor model
![]()
If the degree of risk of relevance to investors is
their out performance, ![]() , the expected return for assets
with
, the expected return for assets
with ![]() should be the same as those with
should be the same as those with ![]() , because they have the same risk in this
environment:
, because they have the same risk in this
environment: ![]() . The risk of a
. The risk of a ![]() asset is identical in magnitude to a
asset is identical in magnitude to a ![]() asset, so the expected returns must be
the same
asset, so the expected returns must be
the same
![]()
Using equation (3.14) on the equivalence of 2-k and k beta assets, and applying the expectations operator, we have
![]()
The LHS of equation (3.15) is the expected return on
the ![]() asset, and the RHS is the expected return
on the
asset, and the RHS is the expected return
on the ![]() asset. Solving for
asset. Solving for ![]() we get
we get
![]()
Equations (3.6), (3.12) and (3.16) imply
![]()
Thus no arbitrage, in the sense things equivalent in
risk are priced the same (as risk is defined here), generates the traditional
CAPM with the significant difference that the expected market return is
equivalent to the risk-free rate. Just as the equilibrium model in prior
section implies, the expected return on all assets is the same, because ![]() .
.
In contrast, a traditional arbitrage model would take from the arbitrage equation (3.12), and, combined with the market model equation (3.6), generate the standard factor model
![]()
That is, the only difference needed to generate a zero risk return relation is the relative utility function, removing this generates the standard model.
Another way to see this is to note that the maximization function reflects the fact that the investor only cares about absolute volatility, not volatility relative to some benchmark.
![]()
Substituting equation (3.18) for ri, the first order condition on equation (3.19) generates the familiar equation
![]()
So investor i’s optimal ![]() will
be equal to the risk premium over the risk aversion coefficient times the
market variance. Assuming a representative investor, conventional parameters
for this approach of 6% for the risk premium, 3 for a risk coefficient, and 15%
for market volatility, this implies an equilibrium beta choice of 1, consistent
with an equilibrium where the representative investor holds the market basket.
Thus, people holding the market, and the market having a return premium, are
consistent in the standard theory.
will
be equal to the risk premium over the risk aversion coefficient times the
market variance. Assuming a representative investor, conventional parameters
for this approach of 6% for the risk premium, 3 for a risk coefficient, and 15%
for market volatility, this implies an equilibrium beta choice of 1, consistent
with an equilibrium where the representative investor holds the market basket.
Thus, people holding the market, and the market having a return premium, are
consistent in the standard theory.
But if, as argued below in section 4, the market
premium is in effect zero for the average investor, the ![]() choice
will be zero, which is not an equilibrium because on average the market beta is
1 by definition and in positive net supply. In the traditional approach, a
positive market premium is necessary for investors to hold the market in
equilibrium, whereas in a relative risk model, combining equations (3.8) and (3.18),
we get
choice
will be zero, which is not an equilibrium because on average the market beta is
1 by definition and in positive net supply. In the traditional approach, a
positive market premium is necessary for investors to hold the market in
equilibrium, whereas in a relative risk model, combining equations (3.8) and (3.18),
we get
![]()
![]()
Here the optimal choice of ![]() is 1
only if the risk premium is zero (i.e., E[rm]=rf),
because risk is uncompensated via arbitrage, and ‘risk’ can be avoided in this
model by choosing a beta of 1. A positive risk premium would induce a desired
optimal beta greater than 1, which would then not be an equilibrium. The
relative status approach implies a zero risk premium, the absolute utility
approach implies a positive risk premium.
is 1
only if the risk premium is zero (i.e., E[rm]=rf),
because risk is uncompensated via arbitrage, and ‘risk’ can be avoided in this
model by choosing a beta of 1. A positive risk premium would induce a desired
optimal beta greater than 1, which would then not be an equilibrium. The
relative status approach implies a zero risk premium, the absolute utility
approach implies a positive risk premium.
While this is a simple model, it has at its essence no more simplicity than what generates traditional risk premiums. The only difference is whether one puts relative as opposed to absolute wealth in the utility function. Both the absolute and relative risk approach generate the familiar factor pricing model, but in the relative risk approach the risk premium is zero in equilibrium, whereas in the absolute risk approach the risk premium must be positive.
B. Equilibrium with Heterogeneous Investors
There exists a two-period economy with two identical individuals, i and -i. There are two types of assets; one is a risk-free bond that pays off Rf with certainty in period 1. There also exists an equity with a return of RE, where
![]()
Total wealth for the individual i in period 1 is given by his portfolio of assets.
![]()
![]() and
and ![]() represent the holdings for investor i
on the risky and risk-free asset, respectively. Each individual is endowed
with k units of wealth, so the budget constraint is
represent the holdings for investor i
on the risky and risk-free asset, respectively. Each individual is endowed
with k units of wealth, so the budget constraint is
![]()
Agent i’s utility function is driven by his wealth relative to the other agent (there is no consumption) in an exponential utility function with a risk aversion coefficient a.
![]()
As the argument in equation (3.26) is normally distributed, the individual therefore maximizes the following function

Note his utility is strictly increasing in his own
wealth, ![]() , and strictly decreasing in the wealth of
the other investor,
, and strictly decreasing in the wealth of
the other investor, ![]() , reflecting the pure envy in
this economy. Also, the variance of his difference from this other investor
negatively impacts his utility in an amount proportional to his coefficient of
risk aversion, a. As there is no consumption, the agent can do nothing
to affect his period 0 wealth, so his relevant decision only concerns
optimizing for period 1. His utility is strictly increasing in
, reflecting the pure envy in
this economy. Also, the variance of his difference from this other investor
negatively impacts his utility in an amount proportional to his coefficient of
risk aversion, a. As there is no consumption, the agent can do nothing
to affect his period 0 wealth, so his relevant decision only concerns
optimizing for period 1. His utility is strictly increasing in ![]() and
and ![]() , so
his budget constraint holds with equality, from equations (3.25) we have
, so
his budget constraint holds with equality, from equations (3.25) we have
![]()
Substituting for ![]() and
and ![]() and applying the expectations operator,
this problem expands to
and applying the expectations operator,
this problem expands to

Taking the first order conditions with respect to ![]() , we have
, we have
![]()
Since each agent is identical, in equilibrium each agent holds the same amount
![]()
Given equations (3.30) and (3.31), we have
![]()
And as there is no ![]() , and
no risk aversion coefficient a in equation (3.32), the same expected
return holds regardless of its sensitivity to the market factor
, and
no risk aversion coefficient a in equation (3.32), the same expected
return holds regardless of its sensitivity to the market factor ![]() , or the volatility of the market,
, or the volatility of the market, ![]() . The returns on all assets — low risk,
high risk, no risk — are the same. Risk does not affect return in equilibrium.
. The returns on all assets — low risk,
high risk, no risk — are the same. Risk does not affect return in equilibrium.
The model allows a strict comparison to the traditional case, where there is no peer comparison in the argument of the utility function. It can be shown that if instead a relative utility function a traditional von Neumann-Morgenstern utility function based on absolute wealth is used, such as
![]()
Then using the same reasoning above generates the traditional result that riskiness affects returns, specifically,

Substituting for ![]()

Differentiating with respect to ![]() , we have the traditional results that the
return on risky assets is greater than for risk-free assets, return is strictly
increasing in the volatility of the market (
, we have the traditional results that the
return on risky assets is greater than for risk-free assets, return is strictly
increasing in the volatility of the market (![]() ), the
risk aversion coefficient (a), and the amount of the risky asset the
individuals holds (
), the
risk aversion coefficient (a), and the amount of the risky asset the
individuals holds (![]() ).
).
![]()
This is the standard result as in Merton (1980), that the expected return of the risky asset is a linear function of its variance. In both the traditional and the relative risk scenarios above, identical optimizing agents hold the same amount of each asset because they are identical; however, asset prices are different in the two scenarios, so that there exists a zero risk-return relation when individuals have relative status utility functions, while in the traditional case higher non-diversifiable volatility increases the expected return for risk. The intuition is that in the traditional approach, non-diversifiable risks cannot be diversified away, variance in wealth diminishes expected utility, and so this undesired aspect of an asset lowers its price to make it comparable in marginal utility per dollar with the safe asset. In contrast, in the relative status model, risk can be avoided entirely by choosing symmetric portfolios, which individuals do in equilibrium in order to maximize their joint utility.
C. Equilibrium with Heterogeneous Investors and Risk Externalities
The assumptions needed for rational agents to disagree are beyond the scope of this paper. I will simply assume that people do disagree (though, see Aragones, Gilboa, Postlewaite, and Schmeidler (2005) as to why this can be rational). That is, some people are more optimistic about mean returns than others. The bottom line is that when agents do act on these differing beliefs, they lower the objective expected returns of such assets.
Given investors often disagree, the volatile stocks are often preferred. There are several reasons why an investor might prefer higher volatility investments. Falkenstein (1996) documents that mutual funds prefer stocks with higher than average volatility, other things equal. One can think of many reasons why an investor would prefer a risky stock to a safe stock.
Overconfidence. An investor who thinks they are smarter than others will apply this superior stock picking to stocks with the greatest upside. If you can identify those stocks with higer erturs, thsis is better applied to Google and Apple as opposed to Coke and GE.
Investor flows to Fund Performance. Sirri and Tufano (1993) document that mutual fund inflows are convex: increasing in relative performance, and then turning upward strongly for the top performers. This generates a ‘call return’ payoff, so that the higher the volatility, the higher the expected return.
Short Constraints. Ed Miller (1977) showed that if investors invest in stocks they think are going to have high returns, stocks with greater variance in their expected return will have a ‘winner’s curse to them, in that those with the higher variance will have owners with greater return expectations. If these expectations are incorrect, this will lead to lower expected returns to stocks with the higher variance.
Investor information. Stocks with higher volatility generate more news than less volatile firms. Such stocks are then ‘in play’, and so become relevant to the investor interested in deviating from the index. Given short constraints, or overconfidence, this leads increased focus leads to lower expected returns to these stocks.
Alpha discovery. Many people believe they have an ability to pick stocks successfully. In order to demonstrate this ability to others or merely themselves, they have to actually try this. It may all be luck, but if people believe that their short run performance signals alpha, that information would be considered valuable regardless. Trading generates valuable information about the trader, and a more volatile asset leads to a cleaner discovery. This biases investors towards the more volatile assets.
Most young people fail to produce anything of last when they try their hand at poetry or dance, yet such unrealistic goals are helpful in discovering a niche that generates lifelong vocations and avocations that give life great pleasure. If one considers that risky financial investments are like paying a price to find one’s comparative advantage, it is part of a broad ‘optimal stopping problem’ where you pay to learn your type, and if you find some serendipitous proficiency one can leverage into selling or structuring investments, the poor after-tax, after-fee, return on many investments is merely a price to alpha discovery.
Lottery preferences. Friedman and Savage (1948) discussed the paradox that people liked lotteries where payoffs are 100+ to 1 though the expected return is negative, but were also generally variance averse. The popularity of lotteries continues, and suggests a deep preference towards high-flyers, at least in moderation.
Representativeness Bias. This is from Kahneman, Tversky, and Slovac (1984). The idea is, a base rate information is neglected in a Bayesian sense relative to the ease to which some anecdotes are presented. So, new listings (IPOs) are potential Microsofts or Googles, in spite of their poor base rate, because most investors ignore or are unaware of base rates, and focus on the anecdotes. Highly volatile stocks generate a lot of favorable anecdotes.
Signaling. If one is starting out in investing, the top investment managers generate a disproportionate share of attention form outside investors. To get into the Bloomberg’s list of top portfolio managers, you need a home run, a ’10 bagger’ in Peter Lynch’s term, something that can generate an outsized return that will generate to future investors or bosses that one is an investor with ‘alpha’.
Some of these work together, such as overconfidence and short sales constraints, or signaling and alpha discovery, but it is useful to break them out nonetheless. All these suggest reasons for investors to like stocks with higher volatility, outside of simple mean-variance preferences. To the degree some of these people exist, the question is, how much can these ‘irrational’ or at least ‘exogenous’ preferences matter.
Consider the model above, except now assume that one investor believes the expected return has some extra return due to reasons mentioned above. That is,
![]()
Taking the first order conditions with respect to ![]() , we have
, we have
![]()
Here, each agent has a symmetric first order condition. Given Eq(3.38), we have
![]()
![]()
Now, investor –i in this case is the one who looks at the risky asset without any overconfidence, signaling value, etc. If the expected return for investor I is merely the risk free rate, this situation reverts to the one in Section 3.B above. If his expectation is higher than the risk free rate, this implies the ‘objective standalone’ return for the risky asset must be lower than the risk free rate for this to be an equilibrium. Assets that have large amounts of investors who believe their investment will generate significant abnormal returns, should have rational expected returns lower than the risk free rate.
D. A Discrete Model
First, we set up the model using identical agents, each with standard utility functions. This will both make the introduction of the final assumptions more understandable, and also highlight how this approach is consistent with traditional results when one uses traditional assumptions.
Consider a model with two agents. Each agent has an identical, standard, CRRA utility function. So that

The agents’ utility is only a function of total wealth in period 1, the period when uncertainty is resolved.
There are 2 assets, a safe asset with no volatility and no net return (gross return equal to 1), and an asset with volatility and a mean net return potentially different from zero. The asset has two states, up and down, which are realized in the next period (there are only two periods, 0 and 1). The risky asset has a gross return of R:

Note R(down)=R(up)-1. In this way, if p=0.5,
the geometric mean expected return is zero for any s because the expected geometric
return is merely ![]() , or
, or ![]() The
return is increasing in probability of the up state p, as the higher
this probability, the higher the expected return. I will call the
The
return is increasing in probability of the up state p, as the higher
this probability, the higher the expected return. I will call the ![]() the volatility, which corresponds roughly
to the volatility of the percent logarithmic return.
the volatility, which corresponds roughly
to the volatility of the percent logarithmic return.
The geometric mean return is simply
![]()
While the geometric standard deviation is
![]()
(as this is a binary random variable it is technically not the standard deviation, which is often thought of as the volatility of log returns).
For the risky asset, the parameters p and s allow us to analyze the mean and volatility of the asset return independently.
In the initial period, each agent has 2 units of wealth to allocate between the risky and risk-free asset, so that their budget constraint in period zero is
![]()
Where ![]() is the investment of
agent i in asset j (the risk free, or equity asset E). Thus,
each agent when applying her total wealth to each of the assets, her wealth in
period 1 (after uncertainty is revealed) is simply
is the investment of
agent i in asset j (the risk free, or equity asset E). Thus,
each agent when applying her total wealth to each of the assets, her wealth in
period 1 (after uncertainty is revealed) is simply
![]()
Given each agent's budget constraint, each agent
basically has one choice, how much to invest in the risky asset E, because as
their utility is strictly increasing in wealth, the budget constraint holds
with equality. This implies that the safe asset will have the residual wealth
allocation![]() .
.
Thus, total wealth in the second period can be rewritten more simply as:
![]()
Each asset is has a supply equal to 2, so that
![]()
As there is one asset, each with two states, the wealth of an agent in period 1 is the following
![]()
Thus Wi(s) is a scalar representing agent i’s wealth in a particular state. Given his allocation to the risky asset, this determines his total wealth in period 1. His expected wealth is thus

The first-order conditions to this problem are that the derivative for each agent, with respect to their choice of wealth allocated to the risky asset, must be zero in equilibrium. That is,
![]()
Subject to the clearance of supply and demand (equation 3.48). The second order conditions are simply that the second derivative for maximizing utility are negative, i.e.,

Given the utility function, and definition of wealth, we have the first order agent maximizing condition as

And the second order condition as

With positive s, Wi>0 for each state, the second order
condition is always negative which implies solving equation (3.54) generates a
maximum for each agent. If equation (44) is satisfied for each agent, and
markets clear, this is an equilibrium. In this case, agents are identical, so ![]() , which trivially must be 1 for each agent
(because
, which trivially must be 1 for each agent
(because ![]() ).
).
Given ![]() and
and ![]() , we can solve for p analytically in this
case
, we can solve for p analytically in this
case

Plugging p into the expected return function, we get the following expected returns (equation (3.55)) as a function of f and s displayed in figure 3.1.
Note this approach generates the standard result, that higher volatility (s) assets are associated with higher expected returns on those assets, and this relationship is greater the greater the degree of risk aversion, f.
Figure 3.1

We see that as volatility rises, at first the expected return needed to compensate is relatively small, but then this asymptotes to a linear function, which approaches 1 as f or s goes to infinity. Varying f generates higher returns along this function, the higher the risk aversion, the higher the expected return consistent with an equilibrium.
It is interesting to note that the ratio of the expected return over the volatility increases to a constant, so that at very low level of volatility, the required return premium for this risky asset is relatively low, but eventually asymptotes at a constant less than 1. This is because at low levels of volatility, the relative impact on total wealth is so low it does not span a great deal of the concave utility function. At local dimensions, the curvature of the utility function is weak, and so, there is little difference between the mean utility from the two states, and receiving the certainty equivalent outcome.
Figure 3.2

E. The Discrete Case with Relative Utility
The first adjustment to the standard model is to use a relative utility function. Now, instead of an agent only caring about his wealth, he cares about his wealth relative to the other agent. To make this analytically tractable I use the ratio of wealth (solving for equilibrium numerically with differences yields similar results). Thus, his utility function is now

As otherwise both agents are identical, have the same
beliefs, and markets must clear, trivially Wi=W-i, for whatever![]() and so
the utility function is in this sense degenerate where the argument is always 1
in equilibrium. Yet, one can still calculate marginal utilities and determine
the equilibrium parameters to this equilibrium. That is, the final equilibrium
is degenerate because in this example, identical agents will always generate
identical wealth allocation, and so have identical relative wealth and utility
in every state. Yet this is an equilibrium outcome, and marginal utilities,
and therefore prices and returns, are different in equilibrium.
and so
the utility function is in this sense degenerate where the argument is always 1
in equilibrium. Yet, one can still calculate marginal utilities and determine
the equilibrium parameters to this equilibrium. That is, the final equilibrium
is degenerate because in this example, identical agents will always generate
identical wealth allocation, and so have identical relative wealth and utility
in every state. Yet this is an equilibrium outcome, and marginal utilities,
and therefore prices and returns, are different in equilibrium.
Consider the case where ![]() , which
is the equilibrium given these agents are identical. Though the resulting
solution in this case is degenerate and uninteresting, the marginal utilities
suggest an interesting contrast to the absolute utility case. For the
absolute utility scenario, the derivative with respect to
, which
is the equilibrium given these agents are identical. Though the resulting
solution in this case is degenerate and uninteresting, the marginal utilities
suggest an interesting contrast to the absolute utility case. For the
absolute utility scenario, the derivative with respect to ![]() for an agent at equilibrium (where
for an agent at equilibrium (where ![]() ) is
) is
![]()
Where R=R(up)=1+s and R-1=R(down)=(1+s)-1. Whereas in the relative utility case, the derivative is

The derivative for each case is decreasing in ![]() . For R>1, when securities are risky, only
at some p>0.5 is equation (3.57) zero with respect to w in
equilibrium (i.e., where each agent holds
. For R>1, when securities are risky, only
at some p>0.5 is equation (3.57) zero with respect to w in
equilibrium (i.e., where each agent holds ![]() =1).
In contrast, in the relative utility case (equation (3.58)), p>0.5 causes
the derivative of utility with respect to
=1).
In contrast, in the relative utility case (equation (3.58)), p>0.5 causes
the derivative of utility with respect to ![]() to be
positive in equilibrium, which means it cannot be an equilibrium. A positive
expected return on the risky asset is an equilibrium only for the absolute
utility case.
to be
positive in equilibrium, which means it cannot be an equilibrium. A positive
expected return on the risky asset is an equilibrium only for the absolute
utility case.
This is because in a relative utility framework, the equilibrium where each agent holds the same portfolio has zero volatility for the argument in the agent’s utility function. He needs no extra incentive to hold positive levels of the volatile equity asset, because to do otherwise is risky, and would require compensation. If each agent is holding one unit of the risky asset, a positive expected return for the relative utility scenario implies each agent would want to hold relatively more of the risky asset, which is not an equilibrium. In contrast, each agent in the absolute utility case must be induced to hold the risky asset via the higher return in equilibrium.
Thus, expected return, as a function of volatility, in the relative utility framework, is simply zero for all levels of volatility and all risk aversion parameters.
F. Relative Utility and Heterogeneous Beliefs
Specifically, the expected return for each agent will contain different values of p, such that a higher p, the probability of the up state, which generates a higher expected return. Thus, we will assume each agent has different p. An equilibrium that holds where one agent thinks assets will rise more than the other will necessarily imply that one agent will hold more of this asset in equilibrium. In equilibrium, the asset market clears (supply of the risky and riskless asset equals 2), and the derivative of each agent’s utility with respect to their allocation to the risky asset is zero.
This scenario complicates the analysis, because not only does each agent think that p (and thus E(R)) is different, but this affects the perceived wealth of the other agent too. Thus, we will assume agents disagree on expected returns, but not that each agent is so boundedly rational that they do not apply their expectation for the risky asset to the other agent as well. Thus, for each agent, we have
![]()
![]() is the same for each agent. But p, which determines the expected
return, is not, so agent i sees
is the same for each agent. But p, which determines the expected
return, is not, so agent i sees

Now the utility function for each individual is

This implies the expected utility is just:

In equilibrium agents are maximizing their utility, the derivative of equation (3.62) is simply

We can assess the effects heterogeneous beliefs by
looking at how the expected returns for each agent are affected by varying the
equilibrium choices of the risky asets. That is, given equation (3.59), we
know that ![]() , and by adjusting these relative weights,
it is consistent with different expectations for the two agents. Using the two
equations from the agent’s maximization, we can solve for pi and p-i, and the
resulting different expected returns from equation (3.63). The results are in
figure 3.3 below.
, and by adjusting these relative weights,
it is consistent with different expectations for the two agents. Using the two
equations from the agent’s maximization, we can solve for pi and p-i, and the
resulting different expected returns from equation (3.63). The results are in
figure 3.3 below.

Figure 3.3

If we increase the risk aversion parameters, or the volatility of the risky asset is higher, these expected returns diverge at a faster rate.
An equilibrium where the agents hold differing amounts can be an equilibrium if they have, basically, symmetrically different expected returns, in this model, as manifested by their differing beliefs about the probability of the good, up, state. The optimist will hold relatively more than the pessimist, the more so the more their expected returns diverge.
The example is simple, but it is an equilibrium using a basic structure that accommodates the standard implications from theories about risk and return. The different implications--zero or negative risk premiums--comes from having a relative utility function, and allowing for heterogeneous beliefs. To the extent people disagree, the optimists will hold more of the risky asset than the pessimists. Applying this to our empirical puzzles in section 1 we see that in general , the lack of a return for risk may be due to mere relative utility. The lower return as a function of asset volatility, which appears to occur for the highest volatility stocks, could be from the amenability of these highly volatile stocks to delusional optimists. Those without such delusions, the realists, accept lower-than-average, even negative, returns on these assets--even when they hold them in positive amounts--because basically they pay a risk premium in opportunity cost to offset the ‘risk’ from deviating from the other agent’s wealth.
A relative status orientation can lower the risk premia to zero, even below if others like volatile assets for some reason (overconfidence, signaling, etc.). My main innovation is merely to make this connection less subtle, less tentative, less convoluted. In those papers the main innovation was basically to show that one could generate overinvestment or underinvestment because of externalities of consumption: Abel and Gali assumed it, DeMarzo set up a 'services' portion of the utility that had clear, positional good characteristics. They did not emphasize that risk premiums are often, if not usually zero, only that it could happen.
To have results such as positional goods arise ‘endogenously’ via having services provided by a fixed labor supply, but then to highlight highly arbitrary parameterizations that yield equilibria different than the standard models does not make the idea of a relative wealth orientation more compelling to me, but that appears a matter of taste. The main point is that if people are better defined as envious, not greedy, there is a lot of benchmarking, and this leads to zero risk premiums, which is generally what we observe. That's a simple idea, which makes it a better idea than saying something less definitive but more ornate.
Last Section | Download PDF | Next Section