Building
a statistical models for middle-market credit risk
One
of the key barriers to extending credit risk modelling to loan portfolios is the
lack of a benchmark comparable to credit ratings in the securitised debt sector.
Eric Falkenstein of Moody’s Risk
Management Services outlines a new statistical model that could fill this role.
Reprinted
from the August 2000 edition of Risk
Professional (the magazine of Global Association of Risk Professionals)
It used to be that a middle-market credit analyst without a statistical model was like a fish without a bicycle. Times have changed. Now most lenders want a model that can add transparency and discipline to their portfolio of unrated (ie non-agency rated) credits. But not just any model will do: a bad model is no better than no model at all. We are searching for a benchmark. This article describes the issues surrounding benchmarks in credit risk, specifically in the area of middle market default prediction.
What
is a credit benchmark?
The prototypical examples of credit benchmarks are the ratings issued by major agencies such as Moody’s Investor Services and Standard & Poor’s. They segregate future defaulters from non-defaulters and correspond to numerical loss rates and their volatilities. Furthermore, in general, a B is a B across industries and countries. Ratings also have historical track record which is publicly available for study.
This has made “external ratings” an
attractive focal point for the new Basel capital regulations. Basel’s initial
paper on credit risk, Credit
Risk Modelling: Current Practices and Applications (April 1999), highlights some necessary properties for a viable internal
model used for capital allocations, one we think is appropriate for any
benchmark. They write that the model must be:
• “conceptually well-understood” [ie transparent and logical]
• “used in risk management” [ie not solely used for regulatory purposes]
• “comparable across financial institutions”
• “empirically validated” [ie tested out-of-sample on large datasets]
Without quantitative models to anchor the process, credit analysis is neither transparent to outsiders nor comparable between analysts, let alone institutions or countries. Outsiders will see the institution as a black box, a collection of loans where all one sees is the proportion of non-performing loans. This is small comfort, since there is always the possibility that performing loans are all teetering on the brink of disaster.
A benchmark does not have to be the most powerful tool available. In fact, by constraining the risk measure to be validated on an out-of-sample dataset, you must omit information you have strong predisposition for using simply because its use would be invalidated conjecture. For example, an experienced lender might decide that loans to firms that have been through a business cycle involve less credit risk than those to firms that have started since the last recession. The lender may have 20 years personal experience to support that assertion. However, statistically it would be very difficult to substantiate this hypothesis – and a benchmark needs objective validation. Thus a benchmark will most assuredly ignore information; only information that is empirically calibrated to its objective is used.
A neglected benefit of a benchmarks is that it allows one to tell if the subjective lender decisions are adding value. That is, those loans subjectively adjusted upward can be compared to those unadjusted to see if such adjustments were warranted. For example, the loans in a certain quantitative range can be compared to those loans that were upgraded due to reasons outside the model, such as qualitative factors like management skill, or even quantitative factors not directly addressed by the model, such as changes in inventories. Over time one can monitor the effects of these adjustments, which helps an institution learn how to make changes that can lead to a competitive advantage.
On average, over many different analysts and subjective adjustments, a good statistical model with a limited quantitative input set is hard for alternatives to beat. This is because a statistical model is trained to predict default, just default, given thousands of actual default events and their financial statements. In contrast, a human usually has an anecdotal dataset from which to develop their “model”, and predicting default is usually not the sole objective of a credit analysts – explanation is also very important.
Overcoming
the constraints
Of course, knowing where to go is one thing, knowing how to get there another. As most banks do not have a benchmark for their commercial loan portfolios, there must be some constraints that prevented those benchmarks from developing. In this case, it is the usual suspect: lack of data. The removal of old obstacles to quantitative models highlight important structural changes in the way we use information to evaluate credit, changes that will have a profound impact upon commercial lending.
Before Newton, there was Kepler, and before him, Brache. The moral is that good models need good data. Since 1968, academic articles averaged a mere 40 defaulting firms in their studies, which underlies why these models have not developed into benchmarks actively used to manage risk after all this time.
Major ratings agencies have the advantage of seeing thousands of defaults in many different countries. Moody’s risk management services group has found these academic models to be approximately equal in statistical power to univariate ratios like liabilities/assets. These models simply weren’t sufficiently powerful to act as a benchmark. A new model doesn’t have to dominate every other model in the world (which would be impossible to demonstrate anyway), but it does have to significantly outperform simpler alternatives.
One approach is to develop a model that estimates default probabilities based on financials statements. Moody’s has taken this approach in its new RiskCalc system. This work did not require cooking up a magic new formula, but instead involved working hard at compiling sufficient data on private firms to ensure that models are truly validated. RiskCalc used some 1,000 defaults in the US and Canada and a further 1,000 defaults in Australia.
The method of estimation is as follows:
1: Transform – Estimate the five-year cumulative univariate default frequency as a function of each input’s level. Use this univariate default frequency function, T(x) = Prob(default | x), to transform the raw input ratios.
2: Model – Estimate multivariate model using transformed input ratios within a “logit” or “probit” function. Select inputs that have positive and significant coefficients, starting with single proxies for size, profitability, leverage, liquidity, and growth.
3: Map – Map output to default frequency by looking at the historical default rate associated with the resultant model output. Adjust final default rate based on an assumption about the population default rate (which is usually different than the sample default rate).
The first step allows the model to sufficiently capture nonlinearities in the financial ratio/default rate nexus. The second step is simple multivariate modelling, which includes the variable selection process. The final step describes the mapping of the model output into a default rate. Nothing magical. The key constraint to do this well is data, as more data allows one to identify existing factors more accurately, and also identify more factors, potentially including interaction effects.
A nice property of this modelling approach is that the initial transformation generates useful intuitive information about the relation of the inputs and the desiderata: default rates. This diminishes the probability of over-fitting since relationships that are not intuitive do not “sneak by” solely because they have high t-statistics.
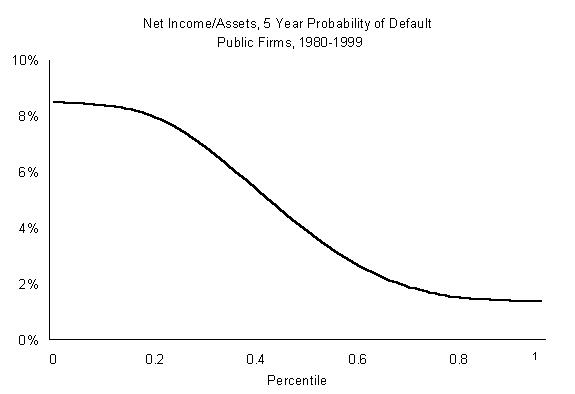
For example, if we look at the relationship between net income/assets and default rates in accompanying graph, we see that the relation is highly nonlinear over its range. For the lower values of NIA its relation to default is sharply negative, but for the latter half the relationship is much less strong. The difference between a weak earner and a medium earner is much greater than between a big earner and a medium earner. This is the kind of useful information that allows risk managers to tie the somewhat abstract EDFs into more basic components.
The
bottom line
Clearly having validated default probabilities built into pricing models, incentive compensation, provisioning, and strategic decisions, can significantly help the decision making process. After all, defaults and their resultant charge-offs are simply expenses, and maximising profit necessitates knowledge of marginal revenue and marginal cost. What has changed recently that every lender recognises that moving towards a statistically validated default estimate is in their best interests.
The new Basel
proposals are a good excuse for lenders to do what they should have been doing
anyway. As
quantitative models move into middle-market lending, banks will perhaps lose
some of their uncertainty premium, which in the U.S. has resulted in a pitiful
median price/earnings ratio of 11 compared to an economy-wide median of 15.
The final result should be a win-win-win-win scenario for lenders, borrows,
investors, and regulators. The only losers are those who expect credit analysis
to be the same way it was in the old days. Purely qualitative methods will go
the way of office ashtrays.
Eric
Falkenstein is a Vice President at Moody’s Risk Management Services, the risk
management division of Moody’s Investor Services. He can be contacted via
email at eric.falkenstein@moodys.com